美国时间3月18日,英伟达在美国圣何塞举办GTC(GPU技术大会)。作为全球最受关注的科技巨头,今年GTC吸引约2.5万人线下参加,另有30万人通过线上方式收看直播。
英伟达CEO黄仁勋在主题演讲开场说道,“因为AI技术爆发,GTC大会的规模每年都在扩大。去年他们说GTC是AI行业的‘伍德斯托克摇滚音乐节’。今年我们搬进了体育场,GTC已经成AI行业的‘超级碗’”。
而在此次GTC大会上,英伟达不仅发布了Blackwell GPU、硅光交换机、机器人模型等一系列新产品。黄仁勋还在演讲中反复传递出一个信号:随着AI行业在模型训练上的整体需求放缓,再加上DeepSeek在模型推理上所做创新,AI推理时代即将到来。
演讲结束后,英伟达股价收盘跌超3.4%,报115.43美元/股,盘后继续下跌0.56%。
Blackwell Ultra GPU:专为AI推理打造的“算力核弹”

作为GTC的重头戏,黄仁勋在演讲中宣布推出数据中心AI GPU的新一代产品——NVIDIA Blackwell Ultra GPU。
此前市场传言英伟达去年年底计划将Blackwell Ultra改名为B300 ,但根据现场公布的结果,官方保留了原始命名。Blackwell Ultra GPU相比于上一代B200GPU性能提升了50%,约为15P FLOPS(基于低精度的四位浮点数格式FP4标准),内存上则搭载了业内最先进的HBM3E,从192GB升级到了288GB。

基于Blackwell Ultra,英伟达面向云计算厂商等大型企业客户客户提供两款系统集成产品:Blackwell Ultra NVL72机架式解决方案与NVIDIA HGX Blackwell Ultra NVL16系统。
其中,Blackwell Ultra NVL72是在一个数据中心机架(一台服务器搭载8个GPU,一个机架可以容纳多台服务器)中连接了72个Blackwell Ultra GPU以及36个英伟达基于ARM架构设计的Grace CPU。据与上一代B200GPU的同类产品相比,Blackwell Ultra NVL72在AI算力性能上提升超过了50%。HGX Blackwell Ultra NV16则是运用NVLink高速互联网络连接8个Blackwell Ultra GPU的服务器系统产品。
与A100、H100等多款主要用在AI模型预训练的产品不同,英伟达此次明确定位Blackwell Ultra“专为AI模型推理打造”(AI-Reasoning),同时兼顾"训练和多场景AI应用的高效性"。Blackwell Ultra NVL72和HGX Blackwell Ultra NVL16(8GPU)两款系统产品也在提升计算能力和内存容量的同时,专为复杂AI推理任务做了优化。以HGX Blackwell Ultra NVL16为例,相较于上一代Hopper架构,这款新品在大模型推理速度上提升了11倍。
此前在DeepSeek用极低的算力成本完成模型开发后,外界就曾担忧市场对英伟达算力芯片产品的旺盛需求是否会放缓,英伟达官方及黄仁勋就曾在多个场合表示,相比于AI厂商先前将大量算力投资用于AI模型训练上,DeepSeek主要在模型推理运用了创新技术,而AI推理依然需要大量英伟达GPU和高性能网络。
在AI行业的“Scaling Law”法则(模型规模越大,模型越智能)在预训练环节放缓后,推理环节将催生更大规模的算力需求,因此“DeepSeek的出现反而证明市场需要更多AI芯片”。
据黄仁勋介绍,Blackwell系列,目前已经全面投产。“产量惊人,客户需求惊人,因为人工智能出现了一个拐点,由于推理人工智能以及推理人工智能系统和智能体系统的训练,人工智能领域必须完成的计算量大大增加。”
按照英伟达“一年一更新”发布节奏,黄仁勋演讲中预告了下一代Rubin架构两款产品Rubin GPU、Rubin Ultra GPU的性能信息。
Rubin GPU算力性能将在FP4标准下达到50P Flops,约是Blackwell Ultra GPU的3.3倍,Rubin Ultra GPU则在相同标准下为100P。两款新架构产品届时也将用上HBM4、HBM4E先进AI内存。搭载Rubin GPU的Vera Rubin NVL144(连接144个GPU)将于 2026 年下半年推出,Rubin Ultra GPU的Rubin Ultra NVL576(连接576个GPU)将于2027年下半年推出。
继Rubin架构之后,黄仁勋现场公布下一代GPU架构的命名为“Feynman”,取自著名物理学家理查德・费曼(Richard Feynman),Feynman架构产品将于2028年发布。
智能体和机器人时代,AI将需要更多芯片
与去年GTC密集发布各种新产品的节奏不同,黄仁勋今年在公布新品前,在现场花了更多时间科普“Agentic AI”的概念,以及AI推理带来的巨大改变。
在现场展示的AI技术发展路线图中,黄仁勋按照“Generative AI(生成式AI)、Agentic AI(智能体)、Physical AI(具身AI)”三个阶段的进化路线,将Agentic AI描述为AI技术发展的中间态。
相比于生成式AI的主要应用——语言大模型与聊天机器人——主要聚焦于生成文本、图像内容,Agentic AI更进一步,能够理解任务、进行复杂推理、制定计划并自主执行多步骤操作,目前业内热议的数字员工等AI Agent即为相关应用。
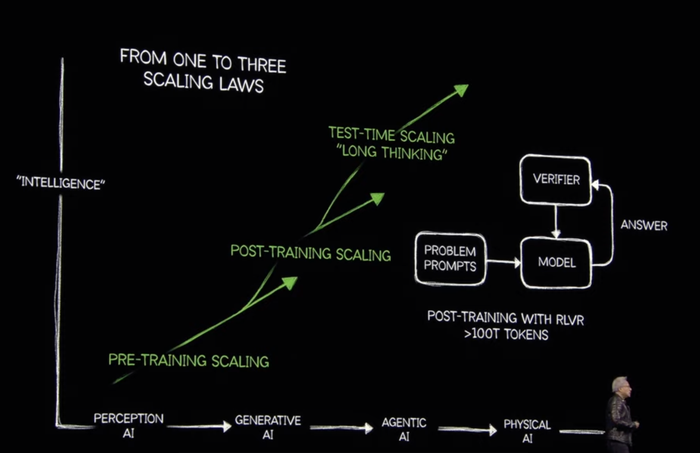
在生成式AI的第一阶段,AI行业的“Scaling Law”法则集中体现在模型训练上,特别是预训练环节(Pre-Training,即从无到有开发模型的前期训练阶段),投入更多的数据、更大规模的算力资源训练出更好的模型,训练规模越大,模型越智能。
黄仁勋认为,从过去一年的行业发展进程来看,预训练为主的Scaling Law法则已走入“误区”。从今年乃至未来很长一段时间内,Agentic AI将代替生成式AI,成为行业新的发展方向。由于Agentic AI强调自主性与复杂问题解决能力,每一步解决复杂问题、分解任务的逻辑思考过程都需要用到“模型推理”,因此推理将成为新阶段的核心动力。
而从生成式AI发展到Agentic AI,并不意味着Scaling Law法则失效。相反,由于将应用范围从训练进一步扩展到推理,不只在预训练环节,模型的后训练(Post-Training,指预训练得到模型后,根据特定任务或需求,使用更小规模、更专注的数据集对模型进行进一步优化训练或微调的过程)和日常推理的长期思考(Long-Thinking)都要继续消耗算力资源,Scaling Law法则对规模的要求非但会变小,相反会进一步扩大。
以一个用户访问AI应用时产生的Token来举例,对于Agentic AI来说,推理所涉及的任务更加复杂,可能需要生成或处理更多Token来完成规划和执行。同时随着更多用户同时访问AI,Token的数量会爆炸式增加。对于大模型来说,每生成一个Token往往需要数千亿次浮点运算,如何在有限时间内尽可能多的生成Token,并快速将推理结果反馈给用户,大规模的算力资源是完成这一切的基础。
按照现场显示的效果,Blackwell Ultra NVL72集群在运行DeepSeek-R1 671B交互式副本时,只需10秒就可以给出答案,而上一代Hopper架构的H100同类产品则需要1分半。
此次大会上,英伟达还发布了一款新型的AI 推理服务软件Dynamo。它协调和加速数千个GPU之间的推理通信,并使用分解服务将大型语言模型的处理和生成阶段分离在不同GPU上。这允许每个阶段根据其特定需求进行独立优化,并确保最大程度地利用GPU资源。
黄仁勋认为,推理所需算力需求规模增长能“轻松超过去年估计的100倍”,未来行业需要更多、性能更强的AI芯片。根据他的预测,数据中心建设的投入到2028年将达到1万亿美元,目前“相当确定很快就会达到这个目标”。
硅光网络交换机、机器人模型与量子计算研究中心
此外,在今年GTC大会上,英伟达还将在硅光芯片、机器人应用、量子计算等领域有进一步的探索。
硅光领域,英伟达最新发布了NVIDIA Spectrum-X(基于以太网,适合兼容更广泛的企业网络)及NVIDIA Quantum-X(基于InfiniBand,偏向专用计算集群)硅光网络交换机。
这两款硅光网络交换机新品是英伟达首次利用“光电共封装技术”(co-packaged optics, CPO)将光通信直接集成到交换机上,推出的商用化硅光交换机产品。此前英伟达的交换机产品的光通信部分主要为“外挂式”,依赖从Finisar和Lumentum等外部供应商采购的标准化模块。
此次英伟达的硅光网络交换机新品与台积电、Coherent、康宁公司(Corning)、富士康、Lumentum和SENKO等行业巨头合作。Quantum-X交换机预计将于今年晚些时候上市,Spectrum-X交换机预计于2026年通过主流基础设施和系统供应商推出。
黄仁勋曾经用“A工厂”描绘AI时代超大规模数据中心的未来形态。随着AI数据工厂规模的扩张,网络基础设施也需要同步彻底革新。英伟达希望通过将硅光子技术直接集成到交换机中,突破超大规模和企业网络的传统限制,为目前万张、十万张GPU的数据中心向百万张GPU的AI工厂过渡奠定基础。
机器人作为未来“具身AI”(Physical AI)的关键应用,英伟达旗下辅助生成机器人训练数据的物理世界模型Cosmos、人形机器人基础模型GROOT N1以及3D实时仿真平台Omniverse是这一领域的主要产品。

其中,GROOT N1是通用机器人基础模型,英伟达此次正式宣布已经将其开源。GROOT N1模型采用双系统架构,灵感来自人类认知原理。在视觉语言模型的支持下,一个系统可以推理其环境和收到的指令,从而规划行动。另一个系统然后将这些计划转化为精确、连续的机器人动作。
除硅光芯片与机器人应用外,在谷歌、微软相继在量子计算芯片领域有重大突破后,量子计算当前成为了硅谷科技巨头布局未来的一个热门方向。英伟达此次也在GTC大会上宣布,将在波士顿建设NVIDIA加速量子研究中心(NVAQC)。据官方介绍,该中心是一个以研究为导向的机构,将通过尖端技术推动量子计算架构与算法的发展。
值得关注的是,去年谷歌发布的Willow芯片攻克困扰量子计算研究30年的“量子纠错”难题,市场升温带动量子计算概念股上股价涨,黄仁勋曾在今年1月接受分析师采访时给量子计算的落地“泼了一盆冷水”:要造出“非常有用的量子计算机”,可能需要20年。黄的这一评价当时导致一众量子计算相关股票应声下跌。
黄仁勋在谈及英伟达成立量子研究中心的目标时提到,量子计算的实用化依赖于解决关键技术挑战,如量子比特噪声和纠错。而NVAQC的使命是推动这些突破:“NVIDIA加速量子研究中心将是突破发生的地方,以创建大规模、有用的加速量子超级计算机。”
对于市场担忧量子计算颠覆现有计算工具,以前所未有的计算速度在密码学、隐私数据保护领域形成“量子霸权”,黄仁勋明确表示,量子计算不会单独取代现有的计算技术,而是作为AI计算能力的补充。未来的量子计算将成为AI超级计算机的“增强工具”,在药物开发、新材料制造等特定高复杂性领域发挥作用。
评论列表